Twitter nie jest najpopularniejszą platformą społecznościową w Polsce, ale ma tę zaletę, że wszystko, co się na nim pojawia jest ogólnodostępne. Dlaczego by więc nie wykorzystać takiego źródła danych do pozyskania informacji o cechach dyskursów politycznych w Polsce – kto jest podobny do kogo, jakie tematy porusza, jakich unika i jak to się ma do koniunkturalizmu?
Postanowiłem jakiś czas temu zbadać cechy dyskursów wybranych polskich partii politycznych: Platformy Obywatelskiej, Prawa i Sprawiedliwości, Sojuszu Lewicy Demokratycznej i Razem. Pobrałem tweety od II kwartału 2015 roku do III kwartału 2018 roku, dane są więc nieco starawe, ale jeżeliby metoda była trafna, to i w takim zbiorze można by zaobserwować ciekawe tendencje.
Oprócz wiadomość partyjnych, uwzględniłem też korpus referencyjny, złożony z tweetów Gazety Wyborczej i Rzepy, po 200 losowych z każdego tytułu w kwartale. Co do partii, to Razem opublikowało 4041 tweety, SLD – 9133, PO – 21 347, PiS – 25 454.
Całość została zlematyzowana przy użyciu TreeTaggera, który jest dość starym narzędziem, ale chyba najskuteczniejszym otwarcie dostępnym (LEM działa tylko jako API on-line, napędzające go WCRFT2 praktycznie jest niemożliwe do skompilowania, a rezultaty modelu j. polskiego w SpaCy wciąż niezadowalające).
Kolejnym krokiem było modelowanie tematyczne metodą alokacji ukrytej zmiennej Dirichleta (LDA, Latent Dirichlet Allocation). Mechanizm ten uczy się dystrybucji tematów w tekstach i słów w tematach, wychodząc od z góry zadanej liczby tematów oraz początkowo losowych dystrybucji tematów. Następnie wielokrotnie dla każdego wyrazu próbkuje się nowe prawdopodobieństwo przynależności do tematu na podstawie prawdpodobieństw pozostałych słów.
Problem w tym, że metoda ta niezbyt dobrze sobie radzi z krótkimi tekstami – np. tweetami. Jednym z remediów jest poszukiwanie dużej liczby tematów. Najniższą liczbą tematów dającą najwyższy współczynnik koherencji, tj. powyżej 0,61, okazało się 50 (współczynnik alfa ustawiony został na 0,1, beta na 0,01, a liczba iteracji wyniosła 100). Tematy jednak są dość heterogeniczne, łączą ze sobą 2-3 różne problematyki. Natomiast średnie odsetki poszczególnych tematów dla tekstów z kolejnych kwartałów są do siebie dosyć zbliżone i wahają się w najlepszym wypadku od 1,5% do 2,5%. Pojawiają się też problemy z przyporządkowaniem tekstów do tematów, jako że dokumenty najbardziej typowe dla tematów mają udział tychże w okolicy 15-25%. Powstaje zatem zasadnicze pytanie – czy istnieją jakieś metody lepszego modelowania tematów dla tekstów tak krótkich jak tweety, gdy chcemy zbadać dyskurs poszczególnych aktorów społecznych, a więc inne niż pooling konwersacji lub hashtagów?
Mimo to, wydaje się, że z danych udało się wyekstrahować pewne informacje. Modelowi do oceny przedstawione zostały następnie dwie grupy tekstów, tym razem z podziałem na poszczególne kwartały: 1) z korpusu referencyjnego GW i Rz, 2) tweety poszczególnych partii politycznych. W każdym wypadku uzyskiwano macierze dwuwymiarowe, w których osią x były kwartały, a y – średnia wartość każdego z 50 tematów w danym kwartale. Następnie dla każdego z elementów macierzy partii politycznych obliczono odległość euklidesową od odpowiadającego mu elementu macierzy korpusu referencyjnego. W ten sposób można by potencjalnie oceniać odchylenia dystrybucji tematycznej badanego dyskursu od mainstreamu politycznego (?).
Ciekawe jest to, że średnie odchylenia od dystrybucji tematycznej korpusu referencyjnego były podobnie uporządkowane dla wszystkich badanych partii, niezależnie od ustawień modelu:
| L. tematów | 50 | 50 | 50 | 50 | 80 |
| α | 0,3 | 0,1 | 0,1 | 0,1 | 0,1 |
| β | 0,01 | 0,01 | 0,01 | 0,005 | 0,01 |
| L. iteracji | 50 | 60 | 100 | 100 | 100 |
| Odchylenia od dystrybucji tematycznej korpusu referencyjnego | |||||
| SLD | 0,0010 | 0,0029 | 0,0029 | 0,0029 | 0,0054 |
| Razem | 0,0014 | 0,0045 | 0,0045 | 0,0044 | 0,0076 |
| PO | 0,0016 | 0,0051 | 0,0051 | 0,0051 | 0,0078 |
| PiS | 0,0022 | 0,0061 | 0,0061 | 0,0061 | 0,0091 |
Można też spróbować rzucić te odchylenia na oś czasu:
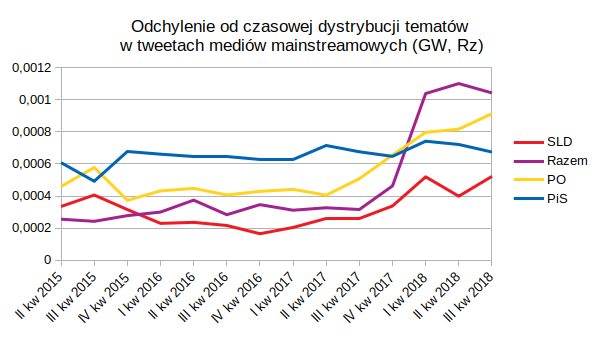
Czym jednak tłumaczyć wzrost odchyleń w 2018 roku? Czy poniższe kalendarium może być pomocne, czy też lepiej zrzucić to na wady modelu, a więc konstrukcję tematów, generowanych na podstawie bardzo krótkich tekstów?
Ważniejsze wydarzenia polityczne 2015-2018
- V 2015 – wybory prezydenckie,
- X 2015 – wybory parlamentarne,
- III 2016 – protest pod Kancelarią Prezesa Rady Ministrów,
- IX/X 2016 – Czarny Protest,
- lato 2017 – demonstracje KOD-u,
- lato/jesień 2017 – zbiórka podpisów pod ustawą Ratujmy Kobiety,
- lato 2018 – zbiórka podpisów pod ustawą Pracujmy Krócej,
- X/XI 2018 – wybory samorządowe.
Przykładowe tematy
3 najpopularniejsze tematy poruszane przez Razem w III kwartale 2018:
0: ważny europejski zapłacić prasa referendum ostrzegać lewica stanowisko ue słowo rosja węgry dyrektor wojciech nagroda
32: protest andrzej przy armia problem naprawdę białoruś telewizja liczba ulica wyjść centrum lotnisko film pięć
33: wielki spotkanie mszuldrzynski pomóc wywiad misja wschód strzelanina bitwa bliski program zdanie ukraina bruksela protest
3 najpopularniejsze tematy poruszane przez PiS w III kwartale 2018:
51: słowo szpital krytykować wiadomość zdrowie uratować wyspa liga dyrektor lider dziennikarz dlaczego opozycja proces zagraniczny
40: dolar bić zbyt zawiesić broń usa blisko nowy finał komentarz strona praca musieć polityk wybory
8: usa trump relacja grozić pięć kupić wybory więzienie zwolnić własny ważny ręka sztuka raz informacja
Widzimy zatem, że jakość modelu jest nie najlepsza, ale uzyskiwane tendencje są sensowne – złośliwie można by np. stwierdzić, że bliskość dyskursu do prasowego mainstreamu nie przekłada się bezpośrednio na społeczną akceptację. Dużo konstruktywniejszym pytaniem jest jednak to, jak można by udoskonalić tego rodzaju reprezentacje korpusów? Czy istnieje jakaś sensowna metoda grupowania tweetów, jeżeli chcemy uzyskać model dyskursu danego aktora społecznego?